NEAT, or NeuroEvolution of Augmenting Topologies, is a genetic algorithm for evolving neural networks. Hayson and I used the neat-python library to train a neural network to play Pong as an optional course project to develop an AI that compete in Pong tournament. The agent maximizes the reward by learning to hit the ball back to the opponent.
Checkout Hayson’s amazing blog post where he explained the theory of how NEAT works!
NEAT is neat
The reason why we turned to NEAT is that DQN did not seem to perform well due to the sparse reward signal in Pong. NEAT is a better choice for stability and also for the efficiency in training, especially for simpler control tasks.
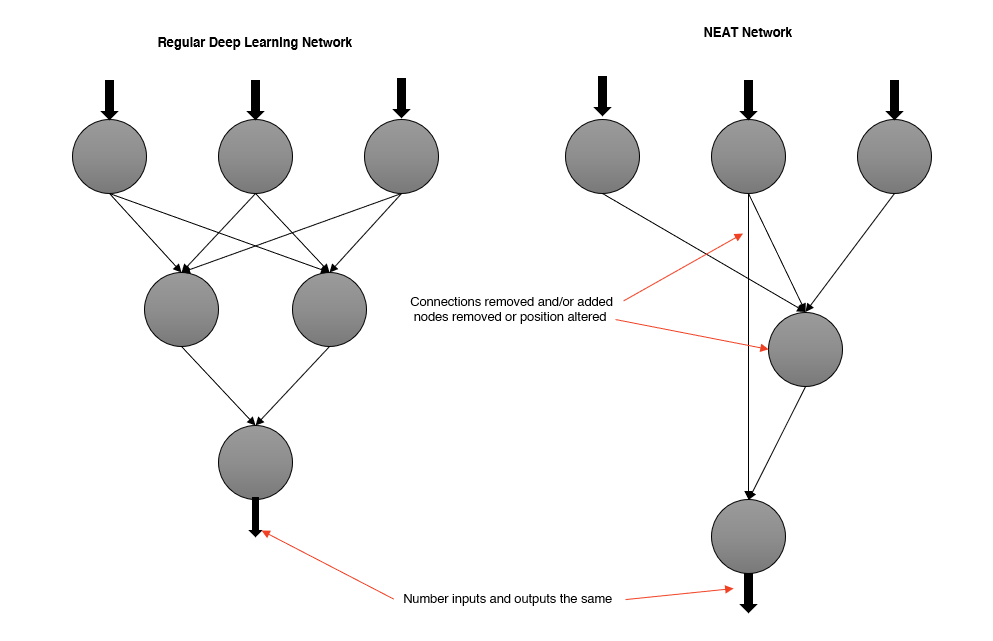
NEAT works by evolving a population of neural networks, where each network is represented as a graph. The graph is a directed acyclic graph (DAG) where the nodes are neurons and the edges are the connections between neurons. The algorithm evolves the population by mutating the graph, adding or removing nodes and connections, and adjusting the weights of the connections.
Training the agent
We trained the agent in a custom Pong environment built with Pygame that our professor provided and we heavily modified for reinforcement learning.
This is how we used the neat-python library to train the agent (a few other key functions are omitted, refer to the repository for the full code):
def eval_genomes(genomes, config) -> None:
# create a list of all genomes and add some chasers to it
n = len(genomes)
matchPlayed = [0 for _ in range(n)]
for genome_id, genome in genomes:
genome.fitness = 0
# Round-robin tournament
for i, (genome_id, genome) in enumerate(genomes):
for _ in range(MATCHES_PER_GENOME - 1):
choice = int(random() * n)
if choice == i:
choice = (choice + 1) % n
matchPlayed[i] += 1
matchPlayed[choice] += 1
opponent_genome_id, opponent_genome = genomes[choice]
simulate_match(genome, opponent_genome, config)
simulate_match(opponent_genome, genome, config)
simulate_match(genome, chaserbot, config)
simulate_match(chaserbot, genome, config)
matchPlayed[i] += 1
for i,j in enumerate(matchPlayed):
genomes[i][1].fitness /= j
# remove all dummy agents from the list of genomes
genomes = [(genome_id, genome) for genome_id, genome in genomes if not isinstance(genome, dummy_neat)]
best = max(genomes, key=lambda x: x[1].fitness)
with open("models/train_best.pkl", "wb") as f:
pickle.dump(best[1], f)
# some other analytics code...
NOTE: At first we trained the agent against a deterministic algorithm, but we found that using self-play was more effective in training the agent to play against a human player. We also found that the agent was able to learn to exploit the deterministic algorithm, which was not the case when playing against a human player.
The agent was able to learn to play Pong quite well after ONLY 30 MINUTES of training. It can beat a human player over 95% of the time even if the player is trying hard to win.